DVsc User Manuals
Web version
Click on the "analysis" module in the navigation bar at the top of the homepage.
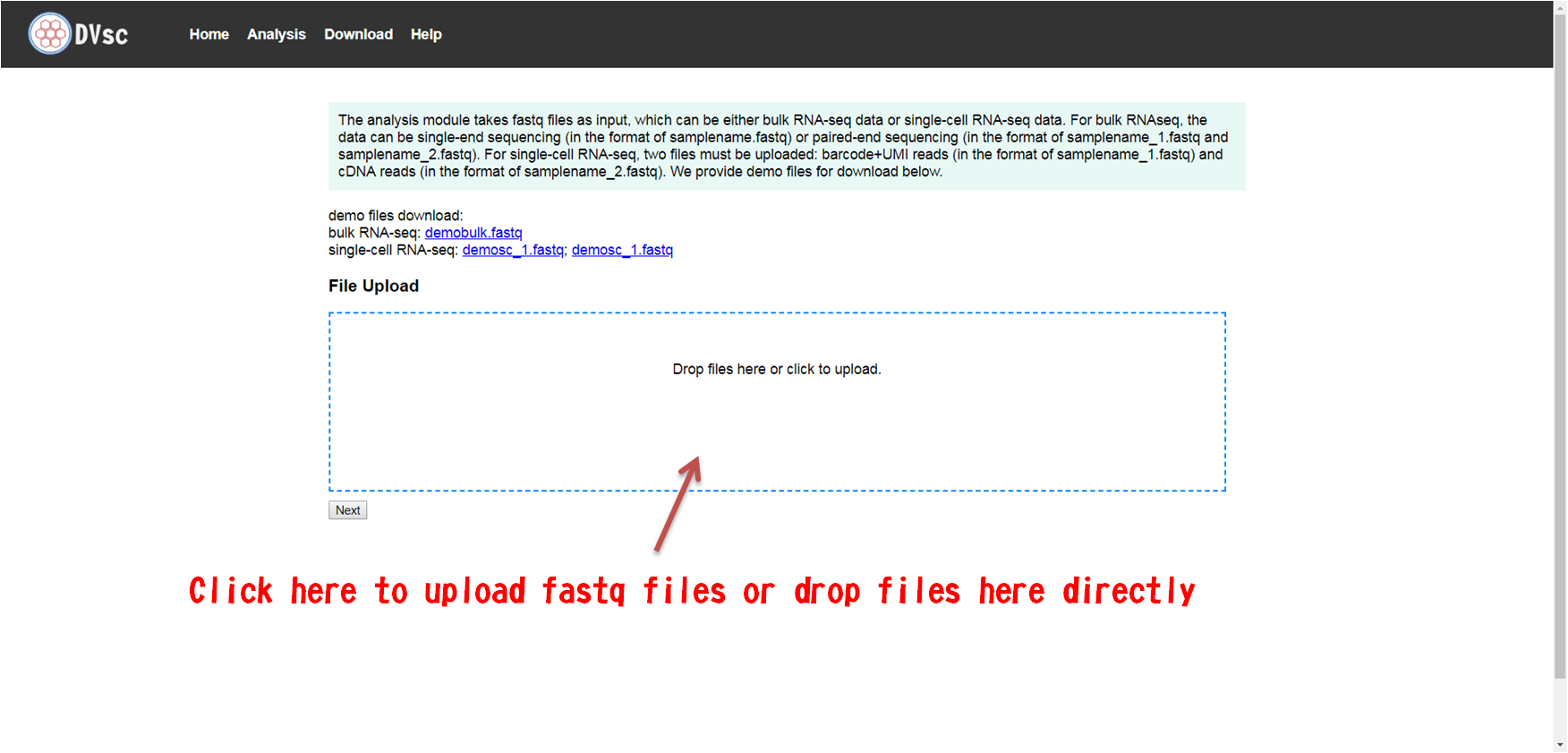
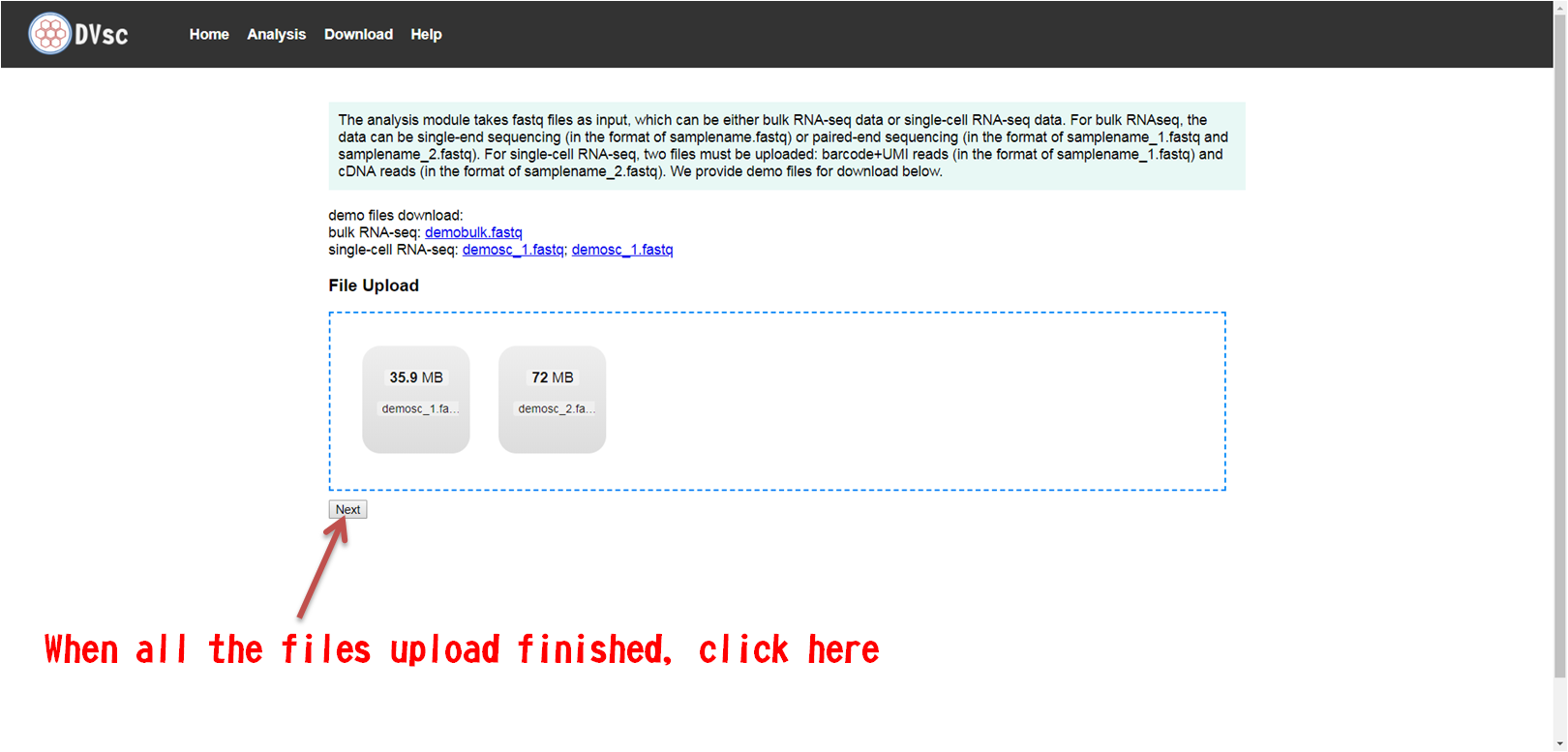
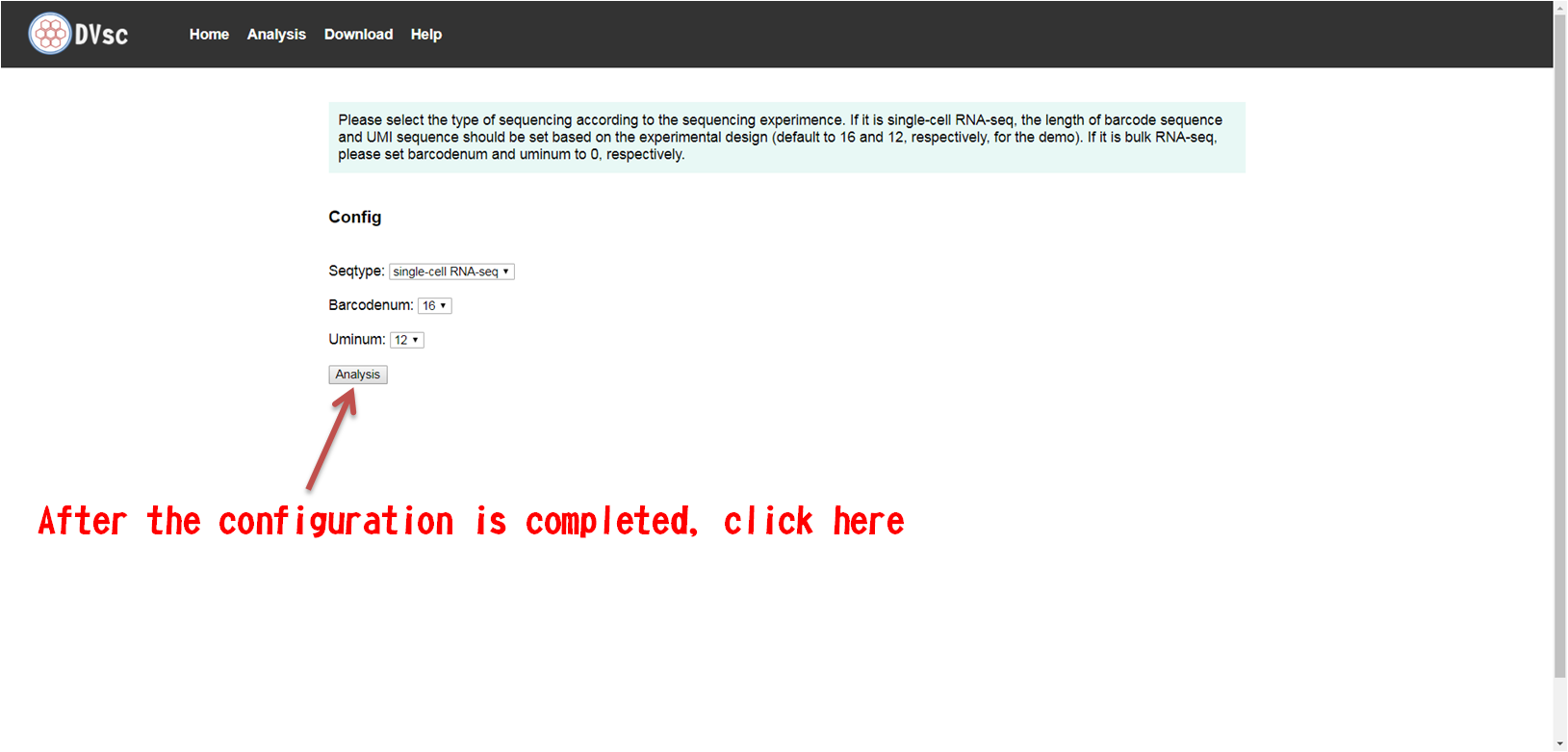
Local version
1. Download profile[Link] and source code[Link] of DVsc. One should also download the human reference[Link], virus reference[Link] and virus annotationVirus annotation databases[Link] databases.2. Set up the conda environment. Note that ${download_dir} is the path you download the files.
conda create --name DVsc --file ${download_dir}/environment.txt
conda activate DVsc
3. Run
Here we take the demo data as examples. the demo data can be download from http://62.234.32.33:5000/download.
- Single-cell RNAseq
python analysis.py --input demosc_1.fastq,demosc_2.fastq --sample demosc --seqmethod scRNAseq \
--outpath ./demosc --barcodenum 16 --uminum 10 --humdb ${download_dir}/homoDB/homo --virdb ${download_dir}/virusDB/virus \
--annotatefile ${download_dir}/virusanno.txt
python analysis.py --input demobulk.fastq --sample demosc --seqmethod bulkRNAseq \
--outpath ./demosc --barcodenum 16 --uminum 10 --humdb ${download_dir}/homoDB/homo --virdb ${download_dir}/virusDB/virus \
--annotatefile ${download_dir}/virusanno.txt
Explanations of the output files
Single-cell RNAseq
The results include two files: "viruscount.filter.txt" and "umi.filter.txt".In the "viruscount.filter" file, you will find the basic information about the detected viruses. The first column represents the sample names, the second column represents the virus names, the third column represents the count of virus, and the fourth column represents the abundance of each virus.
In the "umi.filter.txt" file, you will find the UMI (Unique Molecular Identifier) information for the detected viruses. The first column represents the virus names, the second column represents the UMI sequences associated with each virus, and the third column represents the count of virus.